
Most people using search engines rarely think about how they actually work; finding useful information on the Internet is second nature.
As the Internet continues to grow, search engines need to constantly evolve to deliver effective results.
According to the Internet research firm Netcraft…
[Tweet “In April 2014 there were over 182,000,000 active websites on the Internet.”]How does Google manage to index all these websites and then return relevant results from search queries?
The first thing to remember is that when a user completes a Google search, they aren’t actually searching the Internet; they’re searching Google’s index of the Internet. In short, Google uses a computer program called an algorithm to determine the significance of every web page.
It collects this information by using search software, commonly referred to as Googlebot.
What Exactly Are Spiders, Crawlers, and Googlebots?
Spiders, robots, bots, and crawlers are all different names for programs used by search engines to explore the Internet and download new content to a central database. They harvest all the text content and code on the webpage and follow the links on every page to further discover new content. ‘Googlebot’ is the name of the robot used by Google.
![]()
Googlebot is probably the most sophisticated search engine robot around, collecting web content around the clock to build a searchable index for the Google search engine. It’s guided by multiple algorithms – like PageRank and Hummingbird – to look at keywords, links, and other website data.
How Does Googlebot Interact With a Website?
Googlebot starts off with a list of URLs to visit; these are generated from previous crawls. It then visits these websites and follows links on every page to find new pages and websites. Any new web pages, changes to existing pages, and links that don’t work are added to its database for future reference.
Indexing
Googlebot compiles a massive index of all the words it finds and their location on each page, as well as HTML information (the language used to create web pages) such as title tags. (Learn more here about how to write title tags for SEO.)
This index is like a massive archive containing a copy of every web page found so far, and it’s what Google uses to rank websites and determine how valuable your content is for their search results pages.
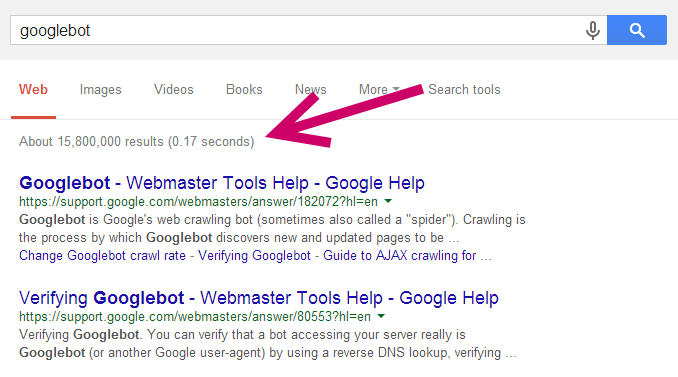
To give an insight into how big this index is; a search for “Googlebot” returns over 15 million indexed pages alone!
The Importance of Spiders, Crawlers, and Googlebots
When people perform a search on Google, Google’s algorithms look up the search terms in the index to find the most appropriate pages. Ultimately, without spiders, search engines wouldn’t be able to index the web, and people wouldn’t be able to find your content.
This is why SEO (search engine optimisation) is so important, and why most business owners and marketers are trying to increase brand visibility and drive more traffic to websites via Google. Basically, it’s one of the biggest free marketing tools available to any business.
Today, one of the best ways to benefit from Googlebot and Google’s algorithms is to simply publish high-quality, useful, and shareable content.
[Tweet “The more valuable or interesting your content is, the more likely it is to be ranked highly.”]This will lead to more people finding your content and linking to it, which will result in your web pages gaining even higher search engine rankings.
It’s important to make your website easy to get around to help Googlebot do its job more efficiently. Clear navigation, relevant internal and outbound links, and a clear site structure are all key to optimising your website.
To signal to Google that your website is valuable; update your content regularly, get more backlinks from quality websites, and optimise HTML tags.
The more you learn about Google and the way it ranks web content, the more you can build brand visibility and stay ahead of the competition.
To get indexed correctly (and regularly), you’ll need a fast and reliable web host; that’s where we can help! Check out our range of excellent web hosting packages and choose the right one for your website. Have a question? Just get in touch with our UK-based support team.
Your Say!
What are your experiences with web crawlers / Googlebot? Got any tips, questions or even horror stories? Let us know below in the comments below!
3 thoughts on “Spiders, Crawlers and Googlebots: How Google Index Your Website”
Comments are closed.